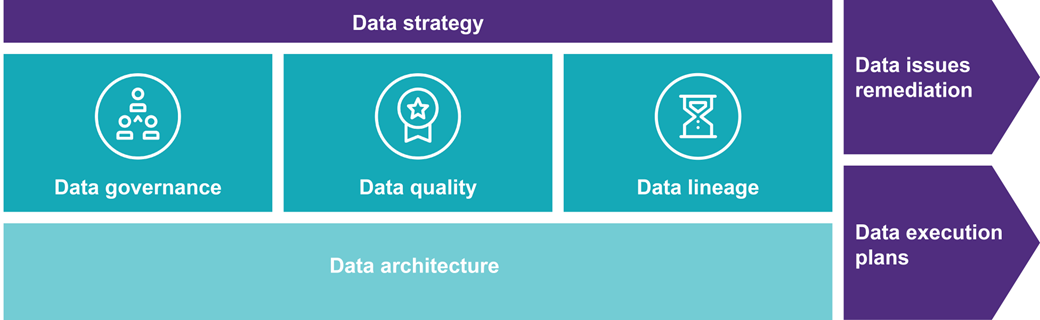
Datastrategie en data-architectuur
1. Data Governance
De belangrijkste principes van data governance zijn:
- eigendom,
- verantwoordelijkheid en
- aansprakelijkheid voor data.
Dit omvat het delen van informatie en het overleggen met relevante belanghebbenden over hoe de gegevens gebruikt, verwerkt en opgeslagen mogen worden. Het instellen van de juiste gegevensdomeinen per product of bedrijfsonderdeel helpt om de informatie te beheren en de gegevensintegriteit te behouden.
2. Data Quality
‘Garbage in, is Garbage out’. Als een organisatie de ambitie heeft om in de toekomst voorspellende analyses te implementeren, dan is dit de eerste belangrijke stap daar naartoe. Dit betekent dat wanneer een organisatie Machine Learning (ML) modellen loslaat op data waarvan de kwaliteit niet goed is, de kans groot is dat er ook geen goede resultaten uit deze analyses komen.
Deze stap is zeer belangrijk. Daarom ontwikkelen we passende controles waarbij we fouten in de data identificeren en eventueel ook voorstellen doen om dit aan te vullen of op te lossen.
3. Data Lineage
Data lineage is de reis die data aflegt vanaf het moment van creatie. Als alle data flows op elkaar zijn afgestemd en uitgelijnd, is het makkelijker om eventuele fouten en veranderingen in de data op te sporen en aan te passen.
4. Data Architecture
Data architectuur is een reeks (beleids-) regels, modellen, en standaarden die bepalen hoe gegevens worden verzameld, opgeslagen, beheerd en geïntegreerd in relatie tot de databasesystemen.
Een goede architectuur maakt het mogelijk om daadwerkelijk goed te kunnen vertrouwen op de masterdata. Het hebben van één enkele bron van waarheid is essentieel voor analyses, business intelligence, herhaalbare geautomatiseerde processen en Machine Learning/AI modellen.
5. Data kwaliteit oplossingen (data issues remediation)
Naar aanleiding van de punten die zijn gevonden ter verbetering van de kwaliteit van de data stellen wij een plan voor implementatie op. Een van de grootste uitdagingen is het bepalen van wat goede datakwaliteit is voor een bepaalde toepassing. Dit vereist een diepgaand begrip van de gegevensbehoeften en -vereisten van de organisatie en de specifieke toepassing.
Daarnaast is het mogelijk dat het verkrijgen van goede datakwaliteit een uitdaging is, vanwege de diversiteit en complexiteit van gegevensbronnen en -typen, de noodzaak van gegevensintegratie en -transformatie en de beperkte middelen die beschikbaar zijn voor gegevensbeheer.
6. Ontsluiting complexe databronnen (data execution plans)
De afgelopen jaren is het aantal applicaties die data genereren toegenomen. Veel organisaties ervaren het ontsluiten van data uit deze verschillende bronnen als complex. Naast dat het ontsluiten van data vaak technisch complex is, is het van belang om data execution plans op te stellen die ervoor zorgen dat de databronnen geen timing issues opleveren.
Wanneer alle bronnen ontsloten en ververst zijn, kan de data aan elkaar worden gekoppeld. Het data landschap van de onderneming bepaald hierin de aanpak. Indien de databronnen veel data generen en de informatiebehoefte van de onderneming groot is, zal er een centrale plek moeten zijn waar de data aan elkaar kan worden gekoppeld en getransformeerd. Dit geldt ook voor wanneer de onderneming een aantal eenvoudige Excel bestanden aan elkaar zou willen koppelen en de analyse zou willen automatiseren. Wanneer nieuwe data wordt verkregen, kan dit op één plek worden ingezien.
Met uw informatiebehoefte als leidraad prepareren wij de data zodanig dat we met behulp van scripts de data omzetten, combineren, transformeren of wegzetten in een centrale omgeving. Hierdoor bouwen wij, samen met u, snelle en gedegen dashboards die antwoord bieden op uw informatiebehoefte.

